

)
- Introducción
- ¿Qué es un Data Lake y por qué importa en medicina?
- Cómo los Data Lakes mejoran la investigación y el cuidado del paciente
- Arquitectura y funcionamiento básico
- Aplicaciones clínicas y casos de uso
- Beneficios y desafíos
- Implementación práctica
- Conclusión
La medicina está atravesando una revolución silenciosa gracias a los datos. Cada día, hospitales, laboratorios y centros de investigación generan cantidades enormes de información: historiales clínicos, resultados de laboratorio, imágenes médicas, registros de consultas y hasta grabaciones de voz. Este océano de datos representa una oportunidad única para mejorar la atención sanitaria, pero también un desafío: los datos suelen estar dispersos, incompletos y almacenados en sistemas distintos que no se comunican entre sí.
Un data lake surge como una solución capaz de abordar esta complejidad. A diferencia de las bases de datos tradicionales, que requieren que la información esté perfectamente estructurada antes de almacenarla, un data lake permite guardar todos los datos en su formato original, sin filtrar ni transformar previamente. Esto facilita que la información pueda ser procesada y analizada cuando se necesite, proporcionando una base sólida para la investigación clínica y la toma de decisiones médicas basadas en evidencia.
La flexibilidad de un data lake no solo facilita el almacenamiento masivo de datos, sino que también permite adaptarse al crecimiento continuo de la información en el sector sanitario. A medida que se incorporan nuevos dispositivos, pruebas diagnósticas o registros electrónicos, el data lake puede expandirse y continuar centralizando todo el conocimiento, convirtiéndose en un recurso estratégico para la medicina moderna.
Un data lake es un repositorio central donde se puede almacenar cualquier tipo de dato: estructurado, como tablas de pacientes y resultados de laboratorio; semi-estructurado, como archivos XML o JSON; o no estructurado, como imágenes médicas, videos de procedimientos y notas de voz. La clave es que se conservan en su formato original, listos para ser analizados según la necesidad.
Por ejemplo, en medicina, un hospital podría combinar resultados de análisis de sangre, historial clínico, notas de seguimiento y resonancias magnéticas en un solo lugar. Esto permite que la inteligencia artificial identifique patrones complejos, como la relación entre ciertos biomarcadores y la aparición temprana de enfermedades crónicas, o la predicción de complicaciones postoperatorias en pacientes con múltiples condiciones.
Además, los data lakes permiten conservar la historia completa de un paciente, incluso si se traslada entre hospitales o sistemas de salud. Esta continuidad asistencial asegura que cada profesional tenga acceso a un panorama completo, reduciendo errores y evitando la duplicación de pruebas costosas. Así, un data lake no es solo almacenamiento: es una herramienta estratégica para mejorar la eficiencia, la precisión y la seguridad en la atención médica.
Para entender la importancia de los data lakes, imaginemos un hospital que quiere anticipar complicaciones postoperatorias en pacientes con múltiples condiciones. Los datos relevantes están dispersos: resultados de laboratorio, imágenes médicas, notas clínicas, grabaciones de consultas y registros de dispositivos de monitorización remota. Sin un sistema centralizado, acceder a toda esta información sería lento y propenso a errores.
Un data lake centraliza toda esta información, la organiza y la hace accesible para análisis avanzados. Esto permite que la inteligencia artificial identifique patrones ocultos en los datos. Por ejemplo, un algoritmo podría detectar que un determinado tipo de respuesta inflamatoria combinada con ciertas anomalías en imágenes predice un riesgo elevado de infección postoperatoria. Con esta información, los médicos pueden intervenir antes de que surja un problema grave, ofreciendo un cuidado proactivo y personalizado que mejora la seguridad del paciente.
Además, los data lakes facilitan la investigación clínica. Al consolidar información de miles de pacientes, los investigadores pueden analizar tendencias poblacionales, descubrir factores de riesgo previamente desconocidos y evaluar la efectividad de tratamientos. Esto no solo acelera la generación de conocimiento, sino que también permite desarrollar estrategias de prevención más efectivas y basadas en evidencia real.
Un data lake combina varios componentes esenciales que hacen posible su funcionamiento:
Primero, está la ingesta de datos, que conecta múltiples sistemas clínicos: historiales electrónicos, laboratorios, PACS de imágenes, dispositivos de telemonitorización y grabaciones de audio de consultas médicas. Todos estos datos, sin importar su formato original, se transfieren al lago de manera segura, usando estándares como FHIR para garantizar interoperabilidad. Esto asegura que cualquier información nueva, desde resultados de laboratorio hasta notas de seguimiento, pueda incorporarse de forma automática y organizada.
El siguiente componente es el almacenamiento centralizado, capaz de manejar grandes volúmenes de datos de manera flexible. En este nivel se conservan tanto archivos originales —como radiografías, resonancias, PDFs de informes clínicos o videos de procedimientos— como versiones optimizadas para análisis con inteligencia artificial. Este enfoque reduce el tiempo de procesamiento y permite que los modelos de IA aprovechen mejor la capacidad de cómputo disponible.
Un tercer componente fundamental es el catálogo de metadatos, que clasifica y etiqueta cada archivo según criterios clínicos y administrativos: paciente, fecha, tipo de estudio, diagnóstico principal, entre otros. Esto permite búsquedas precisas y asegura la trazabilidad de los datos, un requisito esencial para auditorías y control de calidad.
Finalmente, la seguridad y gobernanza son esenciales en un entorno sanitario. Los data lakes implementan cifrado en reposo y en tránsito, control de acceso por roles y versiones de datos anonimizada o seudonimizada, garantizando la privacidad de los pacientes y el cumplimiento de regulaciones como GDPR y ENS. La combinación de escalabilidad, flexibilidad y seguridad convierte a los data lakes en un recurso confiable y estratégico para la medicina basada en datos.
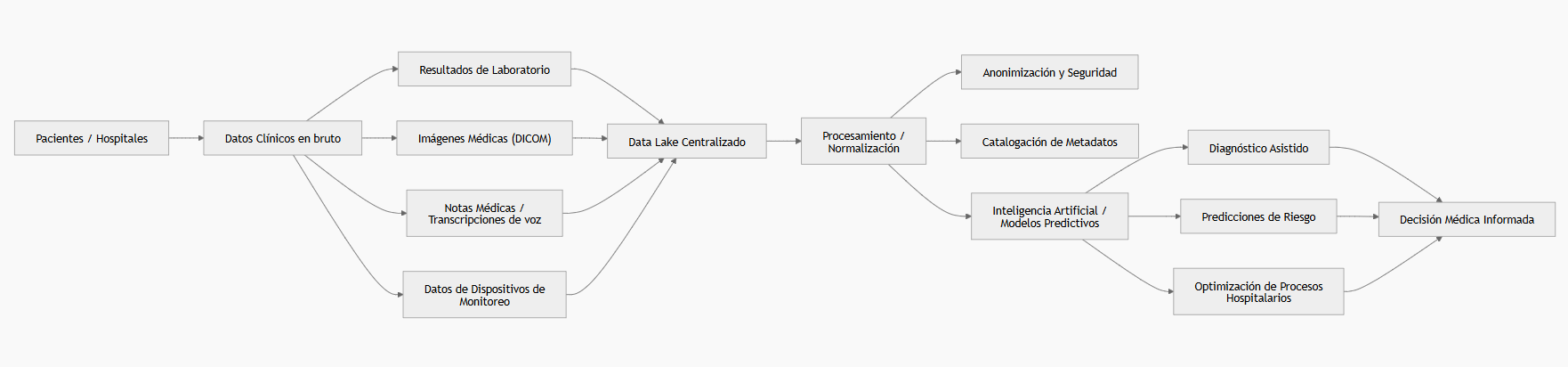
Los data lakes permiten transformar los datos médicos en conocimiento práctico y útil.
Uno de los casos más destacados es el diagnóstico asistido por inteligencia artificial. Analizando miles de imágenes médicas, desde radiografías hasta resonancias, los modelos de IA pueden detectar anomalías que pasarían inadvertidas para el ojo humano. Al combinar esta información con datos clínicos adicionales, como edad, historial de enfermedades o resultados de laboratorio, los diagnósticos se vuelven más precisos y contextualizados, mejorando la atención individualizada del paciente.
Otro ámbito relevante es la analítica predictiva y la salud poblacional. Al agregar datos de millones de pacientes, es posible anticipar brotes epidémicos, planificar recursos hospitalarios y calcular riesgos de complicaciones. Por ejemplo, un análisis continuo de consultas respiratorias podría detectar un incremento anómalo y anticipar un brote de gripe antes de que se emitan los informes oficiales, permitiendo a los hospitales actuar con rapidez y efectividad.
Los ensayos clínicos y la investigación también se benefician de los data lakes. Con acceso a grandes volúmenes de datos anonimizados, los investigadores pueden estudiar enfermedades raras o responder preguntas clínicas complejas con mayor rapidez, evitando años de recopilación manual y acelerando la generación de evidencia científica.
Además, los datos no estructurados, como notas médicas o grabaciones de consultas, pueden procesarse con técnicas de procesamiento de lenguaje natural (NLP). Esto permite extraer diagnósticos automáticos, resumir historiales clínicos y generar recomendaciones basadas en casos previos, liberando a los profesionales de tareas administrativas y permitiéndoles concentrarse en la atención directa del paciente.
Los beneficios de implementar data lakes en medicina son numerosos. Facilitan la continuidad asistencial, permitiendo que cualquier profesional tenga acceso al historial completo del paciente. Mejoran la investigación clínica, acelerando el descubrimiento de nuevos factores de riesgo y la evaluación de tratamientos. Promueven la medicina personalizada, al identificar qué intervenciones funcionan mejor en subgrupos específicos de pacientes, y optimizan la gestión hospitalaria, ayudando a planificar recursos, personal y suministros de manera más eficiente.
Sin embargo, los desafíos no son menores. La privacidad y seguridad de los datos es crítica, ya que cualquier vulnerabilidad podría tener consecuencias graves. La calidad de los datos es otra preocupación: registros incompletos o errores de digitación pueden sesgar los análisis y afectar la precisión de los modelos. Además, existe el riesgo de sesgo algorítmico, que ocurre cuando los datos no representan adecuadamente a toda la población, y la necesidad de cumplir con estrictas regulaciones sanitarias y de protección de datos.
Para que un data lake sea verdaderamente útil, es necesario planificar su implementación cuidadosamente. Primero, se deben definir los objetivos clínicos y seleccionar la tecnología adecuada para almacenamiento y análisis. Luego, se integran los sistemas de información existentes y se establecen protocolos de gobernanza, seguridad y catalogación de datos.
Un piloto típico puede durar entre seis y nueve meses, comenzando con un conjunto limitado de datos reales: historiales clínicos, resultados de laboratorio y registros de consultas. Durante este periodo, se puede demostrar cómo la inteligencia artificial aplicada a los datos del data lake mejora la eficiencia de la atención médica, la precisión de los diagnósticos y la capacidad de anticipar complicaciones, antes de escalar la solución.
Los data lakes no son solo grandes depósitos de información; son la columna vertebral de la medicina basada en datos. Al centralizar y organizar todo tipo de información clínica —desde imágenes médicas hasta registros de voz— permiten que la inteligencia artificial transforme el caos de datos en insights prácticos y decisiones informadas.
Esto significa poder anticiparse a complicaciones, personalizar tratamientos y optimizar recursos hospitalarios, todo mientras se protege la privacidad de los pacientes. La verdadera innovación no reside únicamente en la tecnología, sino en cómo los datos se convierten en conocimiento útil que impulsa mejoras concretas en la atención sanitaria.
En otras palabras, un data lake sanitario no es solo un repositorio: es un motor que conecta información y acción, capaz de transformar cómo se estudian enfermedades, se planifica la atención y se cuida a cada paciente, día a día.